YOUR STRATEGIC CONSULTING PARTNER

DragonWood AI
Dominic McCaskill | Decision Support | June, 2024
Introduction
I, like most parents, enjoy playing board games with my kids and one they particularly enjoy is Dragonwood. I have played it a lot with my kids and started to wonder what the best strategy was and how I can increase my chances of winning. It seems that my kids have an innate understanding of the probabilities involved and have started to beat me more and more.
I searched online for any strategies or an explanation of the probabilities involved but couldn’t find anything so decided I would approach the problem like I would any problem I usually encounter at work. I had also been aware of the AI technique of Reinforcement Learning for a while but had never had a suitable problem to apply it to. So as an excuse to get better at Dragonwood, learn a new AI technique and to write some python I decided to see if I could teach an AI to play the game better than me and try and understand what strategies it uses.
The Game
The game itself is quite simple and easy to learn but there are a number of decisions the players need to make and lots of scope for elementary strategy even though there is a large probabilistic element to the game. The game is summarised in the rules as:
Play cards to earn dice, which you will roll to defeat a fierce array of creatures, or capture magical items that may help you along the way. Whoever earns the most victory points wins.
The below video sums up the rules pretty well and shows the basic structure of the game.
The players play Adventurer cards from their hand of up to 9 to capture one of 5 available Dragonwood cards. The adventurer cards are numbered 1-12 and are of 5 different colours. A player can make the following four decisions:
-
Strike - attack with cards that are in order regardless of colour.
-
Stomp - attack with cards that are all the same number.
-
Scream - attack with cards that are all the same colour.
-
Reload - Draw a card
The player gets a die per card they are attacking with and uses them to defeat Dragonwood cards. The Dragonwood cards being attacked have different defence values for each type of attack and the player must get that value or higher to beat that card.
The Dragonwood cards can be either creatures that give the player victory points when beaten or enhancements which give the user extra abilities or modifiers to their dice roll. For example one enhancement gives the user an extra 1 point to any stomp related dice roll.
One point to note is that the dice are 6 sided dice but with the values 1, 2, 2, 3, 3, 4. This gives the dice an Expected Value per roll of 2.5.
An example attack is included below to illustrate the decision making process.
The decision to use which cards in a player’s hand to try an defeat which Dragonwood cards is the decision we are trying to get an AI to make. I’m hoping to be able to get an AI to identify which cards to use to defeat the Dragonwood cards and also which cards to target to give it the best chance of winning.
Goals
Given the scope of the problem and the initial wide variety of possibilities, I set out some initial goals to allow me to focus my efforts. As this was an exercise to explore what’s possible these are very flexible and will be amended based on the progress I make and research I undertake.
-
Create a model to allow me to play Dragonwood programmatically in Python
-
Develop a rule based algorithm to play Dragonwood deterministically and model how a player selects which cards to attack and when.
-
Develop an AI that can play Dragonwood using reinforcement learning that is as good, or better than the rule based algorithm.
-
Learn some strategies from the AI to improve my chances against my kids.
As a stretch goal for this activity I want to leave as much of the game logic to be determined by the AI. So the AI should be given as little of the game’s rules as possible and should learn through its interaction with the game instead of having the game structure imposed on it.
Goal 1 - Python Model
The first step of the process is to create a model within python to allow me to play Dragonwood, based on the rule-set published online. To do this I created a custom class within python that contained all the objects and methods to complete a game. A simplified version of this model is included below. I have left off the attributes and methods for simplicity.
I made a number of simplifying assumptions that shouldn’t affect the overall gameplay but will make the model more streamlined.
-
I removed certain cards that are only chance based and affect all players with the same probability. These shouldn’t affect how the AI plays over a large number of iterations.
-
Certain enhancements I did not model and I just focussed on cards that modify a users dice roll. I also only dealt with permanent enhancements not ones that require the AI to decide whether to use them on each attack. This allows the AI to focus on the task of attacking and can be added in later once a successful algorithm and system have been developed.
-
As strategy will be slightly different dependant on the number of players, Initially I will play with 4 players; one controlled by AI (I called her Alice) and the other 3 by the deterministic algorithm (Bob, Charles and Dylan).
Goal 2 - Deterministic algorithm
After the model was created I needed to develop a rule based approach to selecting an attack. This is what I will eventually judge any AI’s success or failure against. After trail and error the following algorithm was developed.
-
Find all possible attacks and card combinations from a player’s current hand.
-
For each attack option, work out the Expected Value of the number of dice for that attack. This is the number of cards times by the Expected Value of the dice - 2.5.
-
Add any modifiers from enhancements
-
Take away the score on the card that is trying to be captured.
-
Pick the options with the lowest positive score.
Sensitivity Analysis
As part of deciding on the best algorithm I performed some analysis on what is the most successful formula for a rule based algorithm. This boils down to the best values of and in the below formula:
(c x (Evdice + a)+b)-card defence score
Where:
-
c is the number of attacking cards
-
Evdice is expected value of the dice.
-
card defence score is the Dragonwood card’s score to beat for that attack type.
To find the best values for and I kept 3 players’ and values constant at 0 and then searched through candidate values running a thousand games for each combination and seeing which gave the best points per turn. After running 10,000 games the optimum formula was:
(c x (2.50 + 0.38) - 0.13)-card defence score
Goal 3 - Dragonwood AI
Introduction to reinforcement learning
Reinforcement Learning is a paradigm within machine learning where an AI controlled agent learns optimal behaviour within an environment by exploring actions and seeing their impact on a reward function. The main advantage of reinforcement learning is that it relies much less on humans needing an in-depth understanding of the system involved to program rules explicitly when compared to traditional processes. This advantage is especially potent as systems become more complex, as finding humans with the necessary knowledge can become increasingly difficult (if not impossible).
The diagram and definition below shows how the various elements within a Reinforcement Learning problem interact.
-
Environment. The environment is the entity we are a looking to learn from. In our case this is the Dragonwood game and more specifically the Dragonwood model created in Python. The environment provides the agent with information on it’s state and the impact of the agent’s actions.
-
State. The state of the environment is a set of variables that describe the current game. This is something we have to devise and make sure it includes enough information for the AI to learn from. It could be the cards in the players hands, the players score and/or which cards have been captured. How this information is encoded is also very important.
-
Action. The action or decision that the AI has performed. In our case this will be one or more adventurer cards to attack one Dragonwood card.
-
Reward. This is a function that provides a numerical measure on the suitability of the AI’s action within the environment for the given state. This is for us to define and should reward the AI to prioritise beneficial behaviour. In our case we want to prioritise not only getting points but also winning the game.
-
Agent. An AI controlled user that can perform actions on the environment given a game state and receive a reward for those actions. In our case there will be a single AI agent and a number of rule based users that will perform actions but which we won’t refer to as Agents for clarity. We will refer to our AI controlled agent as Alice throughout.
There are multiple different techniques within reinforcement learning, for this specific problem I investigated the below two:
-
Q-Learning. A technique where multiple runs of the game produce a table with the best action for every possible move a player can make.
-
Neuroevolution of augmenting topologies (NEAT). A genetic algorithm where a neural network is varied over time to find the best performing architecture against a reward function.
Q-Learning
Q-learning is a branch of Reinforcement learning where the agent learns by iterating over the possible actions multiple times to learn which actions lead to the best outcomes. It does this through the generation and iterative update of what’s known as the Q-Learning Table.
The Q-Learning Table is a N x M matrix Q with:
-
N being the number of possible states
-
M being the number of possible actions
-
Qnm being the Q-value of action m under state n
The Q-value is calculated iteratively and updated as the agent takes actions and receives rewards. In simple terms the higher the Q-Value the better the action under state. As the Q-table is updated the agent will take the action with the highest Q-value for the current state.
The Q-value is updated according to a complex formula that includes a learning rate to allow for exploration of new possibilities as well as learning as from previous experience.
State and action space
The first step to implement Q-Learning would be to define the action space and state space to allow me to define the Q-table. This is the total possible states and subsequent actions. As stated in the stretch goal for this task I wanted to try and not abstract away the game rules where possible. This means I want to just and provide the AI Agent with the game and action state and to allow it to learn it’s behaviour based on the reward function.
To provide the Agent with the largest amount of information to make its decision and without limiting its choices programmatically the state would need to represent:
-
Which adventurer cards are in the player’s hand out of the possible 62.
-
Which Dragonwood cards are in the landscape out of a possible 34.
Given this state the actions would then be:
-
Which adventurer cards has the agent selected to attack with.
-
Which Dragonwood card has the agent selected to attack.
Given this definition the action-state space does become quite large.
-
For a player’s hand it could be up to 9 cards chosen without replacement from the deck of 62 which gives us 24,228,029,107 hands.
-
For the cards to attack it could be any combination of 5 cards from the 34 cards available which gives up 331,212.
A very large action-state space means that the model will need to be run longer to make sure all possible combinations are investigated multiple times. One way to reduce the action-state space would be to simplify how the state is represented or to use Deep Q-Learning which uses a neural network to represent the Q-table. However, I felt that there might be other algorithms and techniques out there that would allow me to train the AI without simplification. this leads us to my second technique.
Introduction to NEAT
NeuroEvolution of Augmenting Topologies (NEAT) is an algorithm developed in 2002 to generate and vary neural networks in a way based on genetic principals. The algorithm varies both the weights, biases and structure of the neural network by mutating and reproducing neural networks to find the best structure to maximise the reward function.
So instead of having a fixed network architecture where the best solution is found by varying the weights and biases, NEAT varies both the actual network structure as well as the weights. In practice this means that the optimal solution can be found quicker as the network itself has a lot of impact on its utility.
NEAT Algorithm
The algorithm works by starting with a user defined number of inputs and output. In our case it will be our attack option encoded as an input and our output will be a number in [0,1] to show how good the network thinks that move is.
The input and output structure will stay constant through the evolution but nodes can and will be added to the network between the inputs and outputs and connections to those nodes will also be added according to the configuration of the process. This process is known as mutation.
To decide which networks are the most successful we use a measure known as fitness within NEAT terminology but is effectively a reward function.
Once networks have been generated/mutated and their fitness calculated, new networks are generated by reproduction between two high performing networks. This reproduction ensures beneficial traits of the weights and network are combined to hopefully improve the performance of the network.
The process is repeated for multiple generations with mutation, variation in the weights and reproduction all happening according to various hyperparameters within the process. Luckily all this is handled by a brilliant implementation of the algorithm in the Neat-Python library. The library also tracks a measure of the genetic diversity within the population and maintains a record of the best performing networks and whether a species has become stagnant i.e. has stopped improving.
NEAT Process
Now we have a technique selected and before we go into the important step of input encoding I thought it would be good to cover at a high level how the environment, agent and reward function are going to be used with this technique.
-
A network is provided by the NEAT algorithm.
-
This network is then passed to the Dragonwood game and assigned to the Alice player.
-
A game is then played between Alice and the 3 other players.
-
Each time Alice attacks, the environment provides a list of all possible combinations of attacking cards and Dragonwood cards to attack.
-
Each attack combination is then encoded and inputted into the network.
-
If any combination’s score from the network is over a certain limit, in our case 0.33, the attack combination with the highest score from the network is selected, otherwise a card is drawn.
-
The decision is then enacted by the environment.
-
This is repeated until the game ends.
-
The reward is calculated for that network and game.
-
To make sure the networks are given a chance to understand the implications of their weightings and architecture, 2000 games are run and Alice’s average fitness is passed to the NEAT algorithm.
-
The NEAT algorithm then varies the networks based on the reward gained.
This process is repeated until a certain number of iterations is passed or the reward function exceeds a user specified limit.
Reward Function
The reward function should be derived to make sure that the correct behaviour is being encouraged throughout the learning process. The reward function outputs a float number with higher being better. Initially, given the stretch goal of trying to make the AI learn rules instead of imposing rules on it, the AI was provided with a full list of possible attack options including ones that were statistically not possible to attain. I.e. the defence score of the card was higher than the highest possible dice roll for that option.
The first iteration of the reward function was simple, it would be the average score received by that network:
Input Ecoding
Now I have a reward function, a learning algorithm and a high level process, the final piece of the puzzle is how do I encode the game state to input into the neural network.
For the encoding to be successful it must:
-
Include all relevant information that the network needs to make a decision.
-
Be a array of floats within the range [0, 1]
-
Be as simple as possible to allow the Neural Network to recognise the relationships between the state, actions and reward function.
This step was actually what took the longest time and included much searching of stack overflow and bothering ChatGPT. I eventually decided that for each attack option the following information would be encoded:
-
Current cards in players hand and what cards are being used to attack - encoded as a vector of length 62 representing all cards with:
-
0.5 if the card is in the hand but not in the attack option
-
1.0 of the card is in the hand and in the attack option
-
0.0 otherwise
-
-
Current Dragonwood cards available to attack and which card to attack - encoded as a vector of length 21 representing all creatures and enhancements with:
-
0.5 if the card is available but not being attacked
-
1.0 of the card is available and selected for attack
-
0.0 otherwise
-
-
All players’ current points - encoded as a vector of length 4 with each element represented as the to get it within the range [0,1]
-
Context on how far into the game you are - encoded as a vector of length 2.
This resulted in a input layer with 86 neurons.
Experiments
The aim with all of these networks is to beat the rule based approach. To give me a number to aim for I ran the algorithm but only used the rule based approach, this gave me an average score of around 14 per game. For all of our experiments we need for the AI to be able to get more than this to say we have been successful.
Experiment 1
My initial runs weren’t very successful and resulted in an average fitness of around 2-3 with a best fitness of 4, nowhere near our target of 14. After analysis of the code and reviewing the actions the network was taking I found the following problems
-
The network was selecting options where it was wasn’t mathematically possible to win. i.e. the total card score was greater than any possible dice score. Interestingly this is what my children used to do.
-
The encoding had some bugs in that meant it wasn’t presenting a consistent state.
-
Initially the encoding wasn’t normalised to [0,1]
-
There was an error in the encoding when there was was 2 of the same Dragonwood cards available to attack.
To try and stop the network from selecting options that weren’t valid I changed the reward function to be the average score per game -0.5 the number of invalid choices:
Experiment 2
After updating the encoding and reward function I was able to be a bit more successful. The network was now quickly learning not to play impossible card combinations and was eventually able to have an average score of 3 and with a best network value of 7. Not a huge improvement unfortunately.
After review of the actions selected by the network it seemed to be drawing cards more often than needed and would only attack high value cards when it had a good chance of winning. This conservatism meant that cards with smaller attack values and points were being ignored completely. The cards were even being ignored when the network had valid attacks that had a very good chance of winning. It seems that the new reward function was causing the network to learn to be very cautious and the points it won for the smaller cards was not enough for it to prioritise those cards.
I then tried the following amendments to the reward functions:
-
Added a +10 to the reward when the player won the game.
-
Added -0.25 to the reward when the player drew a card that took it over the max hand size of 9 which would cause it to discard a card.
These changes resulted in a slight increase in the average score to 7 but still didn’t give me the changes I needed.
Experiment 3
It seems that the network was still being conservative and was drawing cards when it shouldn’t be. A measure of success of playing in Dragonwood is the amount of points you get per card. The more cards you discard the less chance to get points you have. As a final attempt to get a less conservative AI agent I changed the function to try and incorporate this.
Unfortunately this had the opposite effect and after a few generations the network was only drawing cards and doing nothing else.
Experiment 4
I was starting to think that the state encoding was too complicated to allow the network to learn from. Before going back to the drawing board I decided to only provide attack options to the network that were possible. This does go against our stretch goal of trying to let the network learn the game rules but at this point I felt it was a good compromise to make.
Once this had been implemented the network did converge on an answer much quicker and I saw a slight increase in the best performing network. However the best score of 8 was still pretty far from the value needed.
Experiment 5
At this point i had been working on getting the network right for a month and had changed quite a few variables with minimal change in the resultant reward function. I felt therefore it was time to review the input encoding. Simplification of the encoding would mean that more of the games logic would be abstracted away from the network but the current approach was not yielding results.
So I decided to simplify the encoding trying to put the least amount of information needed, not worrying about abstracting away information. I ended up with the following encoding:
-
length of attacking hand
-
score to beat on selected Dragonwood card
-
number of points of selected Dragonwood card
-
scream modifier if the card is an enhancement
-
strike modifier if the card is an enhancement
-
stomp modifier if the card is an enhancement
-
player 1 score
-
player 2 score
-
player 3 score
-
player 4 score
-
game length context
This encoding reduces the number of input nodes from 86 to 11.
When the process is running it can take hours to complete so I usually ran it in the evening or over the weekend. So I started it running on a Friday evening and went to bed.
Success
So after over 300 generations I ended up with a network with a score of 16.6885. I now have a network that could compete with, and hopefully beat, my rule based algorithm.
This below chart shows us how the network approaches it’s best result with the max fitness in red staying pretty stable after 50 generations with the average and the 1 standard deviation taking a little longer to reach optimum at around generation 200.


A Grumpy Troll creature card with strike, stomp and scream defence numbers (9, 11, 9) and the number of points for a successful attack (5).
A Ghost Disguise enhancement card with strike, stomp and scream defence numbers (8, 7, 10) and the modification the player gains if the attack is successful (2 points added to any scream attacks).
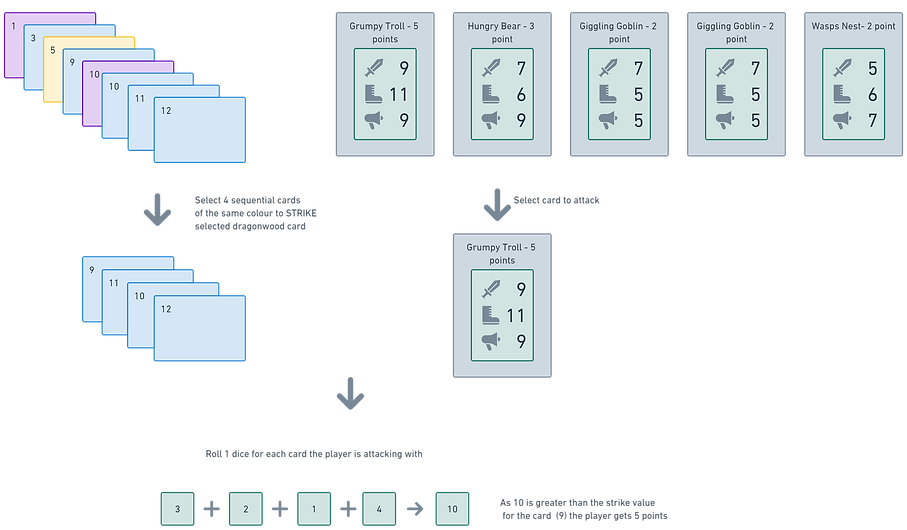
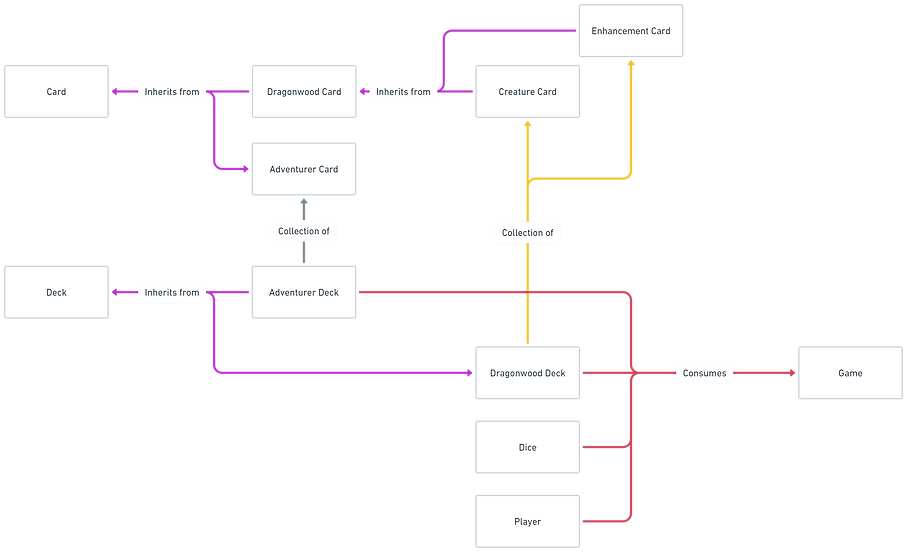
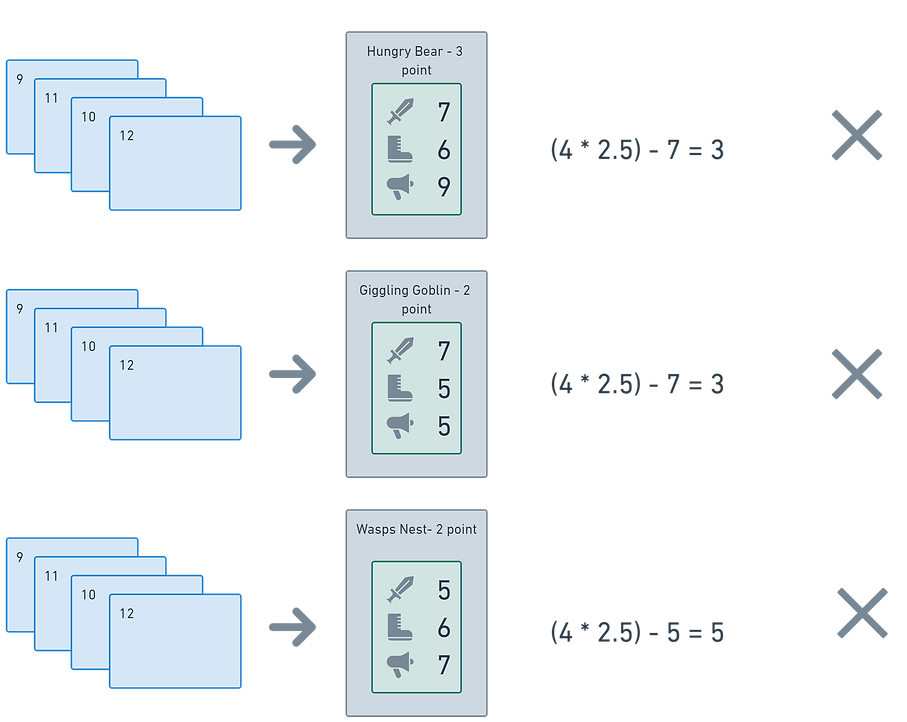
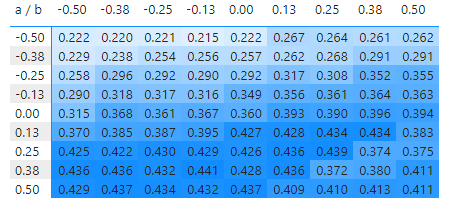
Figure 3: Example attack
Figure 2: Dragonwood cards
Figure 1: Game structure video
Figure 4: Dragonwood model diagram
Figure 5: Example rule based decision
Figure 6: Search matrix for values of a and b
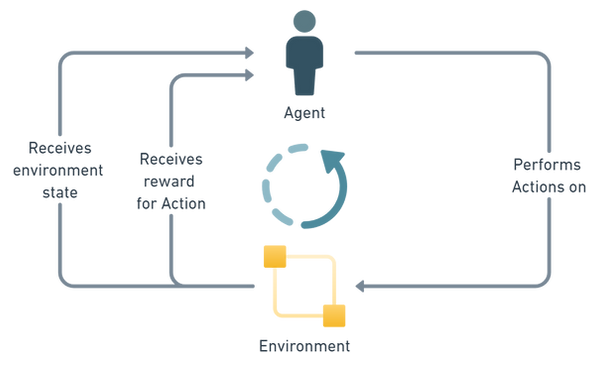
Figure 7: Learning diagram
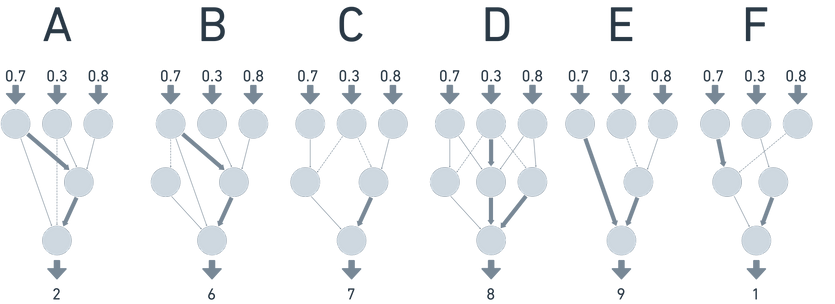
Figure 8: Base networks

Figure 9: Reproduction

Figure 10: NEAT process